Linear Regression From Scratch PT2: The Gradient Descent Algorithm
In my previous article on Linear regression, I gave a brief introduction to linear regression, the intuition, the assumptions, and two most common approaches used for solving linear regression problems. The previous article focused on one of the approaches; “the Closed Form solution(Analytical Approach)”. In this article, the focus will be on the second approach: “Numerical Approach”, in specific, one type of the numerical approach called the “Gradient Descent(GD Algorithm)”.
SOLVING LINEAR REGRESSION USING THE NUMERICAL APPROACH
In real life scenario, most problems (or atleast the ones we are interested in Machine learning), do not have exact solutions as proposed by the Closed form solution. Aside this, there are several complications that could arise from using the closed form formula(as shown in the image below). One of such problems is the computation complexities and expenses or inverting the matrix(X.T.X), when X is a large sample. Another point of concern is the possible case of the matrix not being invertible or does not exist(Yes this happens!!Refer to materials below to understand why)

So unlike the “Closed form Solution”, the numerical approach has an update rule for the weights(theta ⍬). It uses an iterative process to find the best value of theta that minimizes the cost function, or the best value of theta, where the loss is minimal. We can call this “Optimization”.
“Optimization is the core of Machine Learning” . Searching for the best/Most optimal solution to a given problem.
There are several numerical approaches used for linear regression. However, I will be focusing on the “Gradient Descent” class of optimization techniques. In this article, we will explore only one variant(The Batch Gradient Descent(BGD)), and talk more on others in subsequent articles.
GRADIENT DESCENT AS AN OPTIMIZATION ALGORITHM
Gradient descent is an iterative first-order optimization technique used to minimize a function. It does this finding the global minimum of a convex function(Oops!!Buzz words. Please reference the materials for an understanding of these terms). It assumes convexity of a function.
A function is said to be “Convex” is its second order derivative is greater or equal to zero(0). i.e f ⎖⎖( x) ≥ 0. If -f ⎖⎖( x) ≥ 0 then it is a Concave function(Ascent)
This is one of the most popular optimization techniques used in Machine learning(especially in the area of deep learning). Several research papers have been published proving that this algorithm works best for most problems (atleast as far as we know currently).
It is considered a natural algorithm that repeatedly takes steps in the direction of the steepest decrease of the cost function
How does it work?
As mentioned earlier, for numerical approaches, an iterative process is used such that the weights(theta) of the model is updated incrementally(in steps) at each iteration , with attempt to find the optimal value where the loss is minima.
With Gradient descent, a convex function is assumed, the loss function is differentiated with respect to the weights to calculate the gradient. This gradient is multiplied by a parameter (⍺- Learning rate or step count) and subtracted from the previous value of the weights.(it’s a descent afterall). The loss is calculated at each step(iteration) . This process is repeated iteratively until convergence.

Where w on the right side of the equation is the new theta value, and on the left side is previous/old theta.
The learning rate(⍶) determines the steps to be taken along the slope to achieve the goal. Too large steps could result in jumping over or missing the point of global minimum(also known as overshooting) and too small steps results in a very slow process of achieving the goal. This is a hyperparameter that needs to be tuned. In practice, people often start with 0.01, and either decrease or increase accordingly.
The learning rate is not constant across all problems. One value might work well for one set of problem but fail for another. it is a constant battle in Machine learning to find the best learning rate .

Variants of Gradient Descent
There are generally three(3) variants of the Gradient descent Algorithm;
- Batch Gradient Descent
- Stochastic gradient descent
- Mini-Batch gradient descent
In Batch gradient descent(which will be the code implementation use-case for this article), all samples(X) are used at each iteration to compute the gradient and update the weights. For large datasets, this can tend to be computationally expensive and very slow. This is actually one of its disadvantage(the speed in computation(time complexity) for larger sample size).
The pseudocode for this algorithm is:
- Initialize a random guess for the weights (Start with some random guess for theta)
- Compute gradient using all samples(x)
- Update weights using the update rule
- Repeat until convergence

Great! Now let’s see this in action with code.
CODE IMPLEMENTATION OF THE BATCH GRADIENT DESCENT ALGORITHM
We will be using the same data as was used in the first part of this series(Find link here(Hover your mouse around here).
So the basic steps on data import, preprocessing et cetera will be skipped. We will dive right into building the Batch Gradient descent(BGD) model.
STEPS:
- Define the model class and the hyperparameters it will take(Epoch and Learning rate)
The Epoch is the time it takes to pass over the entire data once. This differs from iteration. Here, it does not really matter since we consider all the data samples at each step. However, when we get to the other variants of the Gradient Descent Algorithm, we will notice the difference between the two terms(Epochs and Iterations)

2. Define the train method and the parameters it will take(X and Y)
3. i) Initialize theta using a random variable to the shape of X features and a bias(The reason for this is the matrix multiplication between theta and X. Remember matrix multiplication requires nxm ->mxn condition.
Also keep this in mind, in cases where you might have a “matmul” error, check the shape of variables you are performing the matrix multiplication on. Computing by hand will help you debug faster, as sometimes you might need to transpose one of the matrices so multiplication is possible. Also remember the representation/how the matrices are placed determine how the multiplication is computed.
ii) Calculate Gradient
iii) Define the update rule and update theta
iv) Calculate the loss during training

You will notice few things in the code above. A variable called “precision” was added to the set of parameters the fit function will take. This is optional, It is somewhat like a threshold value and is used when we want to set a point of convergence and break out of the loop(Notice the line of code where the threshold condition was set).
Hint: Try using the model with and without the precision to see the difference
4. Define the predict method(same as before).

5. Compute MSE on test data

6. Initialize model with hyperparameters(setting learning rate and epoch size of choice) and fit data.

6. Predict on test data.

7. Get MSE(loss on test)

Great! You just built a Batch Gradient descent model from scratch.Congratulations!!
Hope you enjoyed reading this article and gained something new. Next time, we will look at using the same data but with another variant of the Gradient descent algorithm- “The Stochastic Gradient Descent”. See you then! Thank you for reading!
Find the GitHub repository link for the code used below;
PREVIOUS ARTICLE(LINEAR REGRESSION FROM SCRATCH PT1)
CONNECT WITH ME ON SOCIAL MEDIA
Twitter: @diyyah92
LinkedIn: https://www.linkedin.com/in/aminah-mardiyyah-rufa-i/
RESOURCES AND REFERENCES

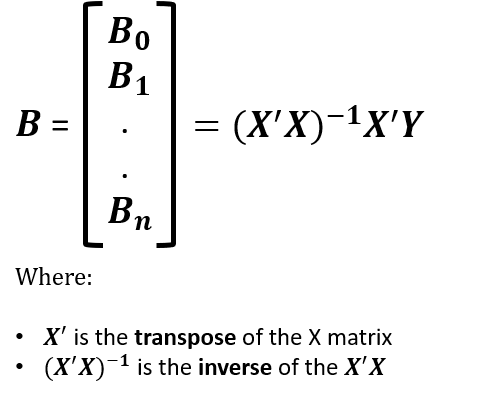{kind=link}